|
L’automatisation du reporting
Etat des lieux du reporting réglementaire
Avec l’entrée en vigueur de solvabilité 2, le reporting réglementaire a changé radicalement de forme et de fonds.
• les états relatifs aux comptes sociaux demeurent (comptes annuels, rapport de gestion, rapport général du commissaire aux comptes…),
• certains états sont supprimés (rapport de solvabilité, rapport sur la politique des placements, rapport sur la réassurance, rapport de contrôle interne et annexes, états C et T, …),
• de nouveaux rapports et états apparaissent (rapport sur la solvabilité et la situation financière, rapport régulier au contrôleur, rapport ORSA, politiques écrites, états de reporting quantitatifs, ENS …).
Solvabilité 2 introduit une difficulté supplémentaire, portant sur la conversion des états (QRT et ENS) en XBRL. Les exigences techniques de ce langage et les tests de contrôles embarqués nécessitent une qualité d’informations irréprochable.
Enfin, le calendrier imposé par la norme nécessite de gagner encore un mois dans la procédure de clôture dans les 2 prochaines années. Ainsi, pour les comptes solos de 2017, les déposes Onegate devaient être effectuées au plus tard le 06/05/2018, alors que pour les comptes de 2019, l’échéance sera le 08/04/2020.
Face à ces exigences, les entreprises mettent de plus en plus souvent en place des fast close. Les données sont en fait extraites quelques mois avant la clôture (1 à 3 mois en général), ce qui permet d’effectuer en anticipation tous les traitements et calculs nécessaires à la clôture. Cette approche nécessite une quantité de travail importante, un ajustement des méthodes actuarielles, ainsi qu’un suivi entre le prévisionnel et le réel.
Il existe en fait une autre alternative, certainement plus pertinente, mais beaucoup moins pratiquée : l’automatisation des traitements. Certains outils informatiques permettent aujourd’hui de créer des process de traitements, de l’extraction de la donnée jusqu’à la production de l’information financière dans les rapports narratifs ou les états XBRL.
Points de blocage dans l’automatisation
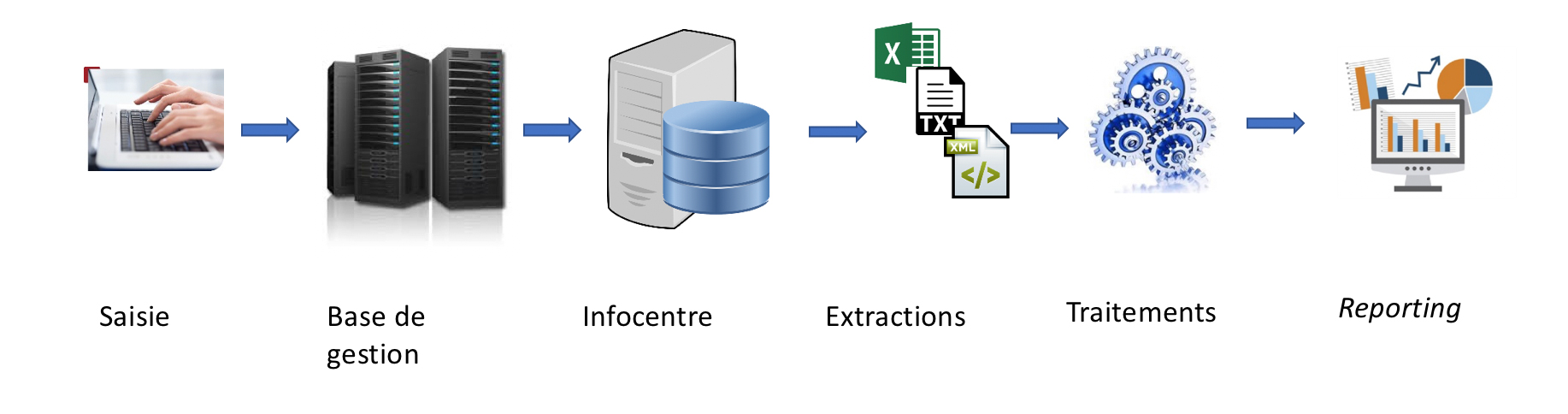
La chaîne classique de production d’une information financière peut être résumée dans le schéma suivant :
Des points de blocage se produisent en fait à chaque étape de ce processus.
Entre la saisie et l’infocentre
L’automatisation des process va nécessiter une bonne qualité des données. En effet, une information erronée va se propager tout au long de la chaîne. Les régulateurs nationaux et européens ont bien conscience de cette problématique, et ont donc développé dans la norme Solvabilité 2 le concept de qualité de données. Les entreprises doivent mettre en place une démarche permettant de s’assurer de l’exhaustivité, de l’exactitude et du caractère approprié de la donnée.
Aujourd’hui, les chantiers sur la qualité de la donnée sont généralement lancés, mais peu avancés. Les principales raisons que l’on peut identifier sont :
• le manque d’implication de la gouvernance
• le manque de temps et de moyens
• l’absence de texte précis précisant la forme et le fonds d’un tel process
• la complexité des systèmes d’information
• les données des délégataires (fichiers hétérogènes, données pas assez détaillées, envois tardifs, non intégration dans les bases de gestion/infocentre)
Extractions
Au niveau des extractions, on rencontre des problématiques liés à l’hétérogénéité des bases de gestion (SQL Server, Oracle, SAP, IBM DB2 ou AS400, Teradata, PostgreSQL…) et l’hétérogénéité des formats des fichiers extraits (Excel, texte, XML, PDF…).
Les fichiers générés sont (très) souvent des fichiers Excel ou des fichiers texte, et de nombreux traitements seront nécessaires et effectués manuellement avant que les données ne soient exploitables. On n’observe que très rarement l’utilisation d’outils dédiés aux bases de données (SGBD). Parfois, on a à l’inverse des outils disproportionnés par rapport aux besoins. L’exemple le plus classique porte sur l’achat de SAS pour faire uniquement des extractions de données en SQL. Acheter cet outil puissant à cette seule fin n’a pas beaucoup de sens, car de nombreux utilitaires (dont certains sont même gratuits) permettent d’arriver au même résultat.
Il y a également parfois un manque de connaissance de la base de données ou de l’infocentre, en raison de sa complexité ou du manque de documentation.
Traitements
Les traitements des données extraites des systèmes d'information sont souvent complexes, non automatisés, et effectués dans des outils non adaptés et non documentés. Excel reste l'outil prédominant pour ce genre de travail, alors que ce n'est pas sa finalité première. Par ailleurs, il est souvent mal utilisé (succession de copier-coller en valeur, suppression de lignes "à la main", correction de valeurs en dur dans les cellules, fonctions de calculs en colonne parfois modifiées sur certaines cellules…)
Quoi de pire pour un auditeur (et même souvent pour les personnes en charge des process) que de devoir faire face à plusieurs centaines de fichiers Excel, naturellement tous différents, faisant eux-mêmes référence à des dizaines d’autres fichiers, et contenant des formules de calculs sur plusieurs lignes, imbriquant une succession de fonctions SI et RECHERCHEV.
Il faut ensuite alimenter les outils actuariels, qui sont rarement « intégrés », c’est-à-dire capable de communiquer nativement avec une base de données externe. Il y a donc un travail d’alimentation de ces outils, de paramétrage, puis d’exploitation des résultats. Ces derniers sont souvent produits dans un format propre à l’outil, que les utilisateurs doivent retraiter pour alimenter leurs propres maquettes de résultats (là encore, très souvent sous Excel).
Reporting
Avec l’instauration d’XBRL comme langage de reporting, il faut en plus alimenter de nouvelles bases, dédiées à ces tâches. Sur le marché, il n’existe que très peu d’outils capables de faire des calculs actuariels et de générer des instances XBRL. En conséquence, de nombreux acteurs doivent resaisir les résultats dans des maquettes spécifiques, fournies par les éditeurs de logiciels XBRL.
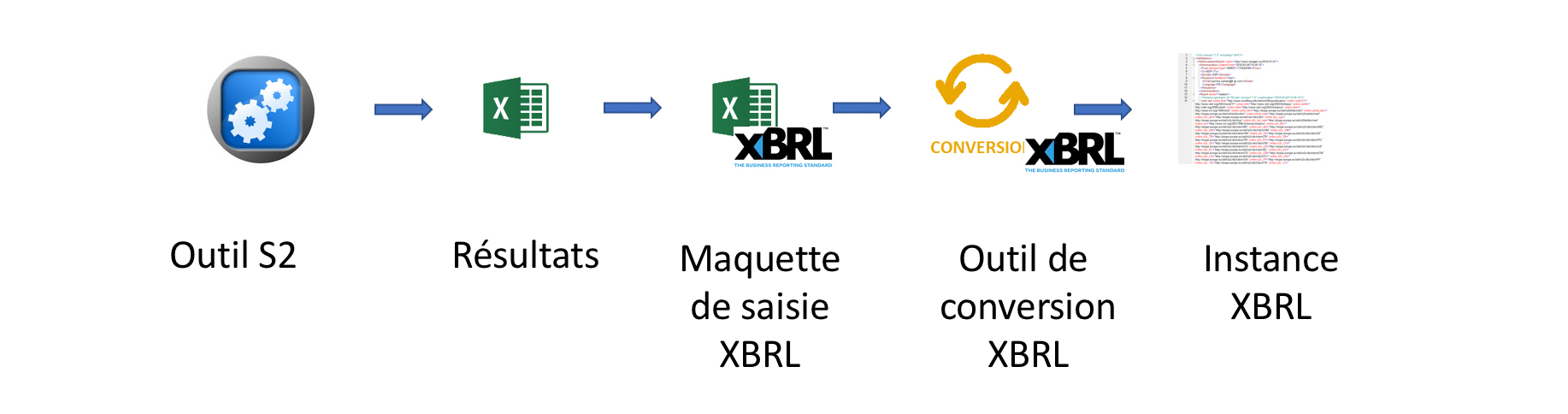
Ce travail est d’autant plus complexe que certains états nécessitent de récupérer des informations historiques, comme par exemple l’état S.19 sur les provisions techniques non vie, ou le S.29 sur la variation des fonds propres.
Enfin, il faudra rédiger les rapports narratifs. Toutes les données chiffrées sont saisies manuellement, avec tous les risques d’erreur inhérents comme par exemple une faute de frappe ou une valeur non mise à jour (on démarre généralement le rapport de l’année N par une copie du rapport N-1).
La moindre correction de chiffre en amont du process va entraîner une modification en chaîne de toutes les autres informations (fonds propres, SCR, MCR, …) et tous les chiffres des rapports devront donc être mis à jour manuellement.
Solutions aux blocages
Pour contourner ces différents points de blocage, une entreprise d’assurance pourra mettre en place une approche en 3 composantes.
• Qualité des données
• Traitement des données via des ETL
• Centralisation des traitements
Qualité des données
Ce n’est pas lors des extractions de clôture qu’il faut s’interroger sur l’exhaustivité et la réalité des données. La norme Solvabilité 2 impose la mise en place d’une politique et d’un process autour de la qualité de la donnée.
Ce chantier passera par l’identification des sources d’informations, la description des traitements et la mise en place de contrôles les données. Bien que le périmètre imposé par Solvabilité 2 ne porte que sur les provisions techniques, il est vivement recommandé d’étendre le processus à toutes les données de l’entreprise.
Traitement des données
Les éditeurs informatiques proposent depuis de nombreuses années une gamme d’outils, appelés ETL (Extract, Transform, Load), qui sont aujourd’hui arrivés à maturité.
Ces outils permettent d’interroger toutes les bases de données existantes, d’effectuer des traitements, puis de charger les résultats dans une base cible. L’intérêt majeur de ces logiciels est qu’un traitement spécifique peut être rejoué à l’infini.
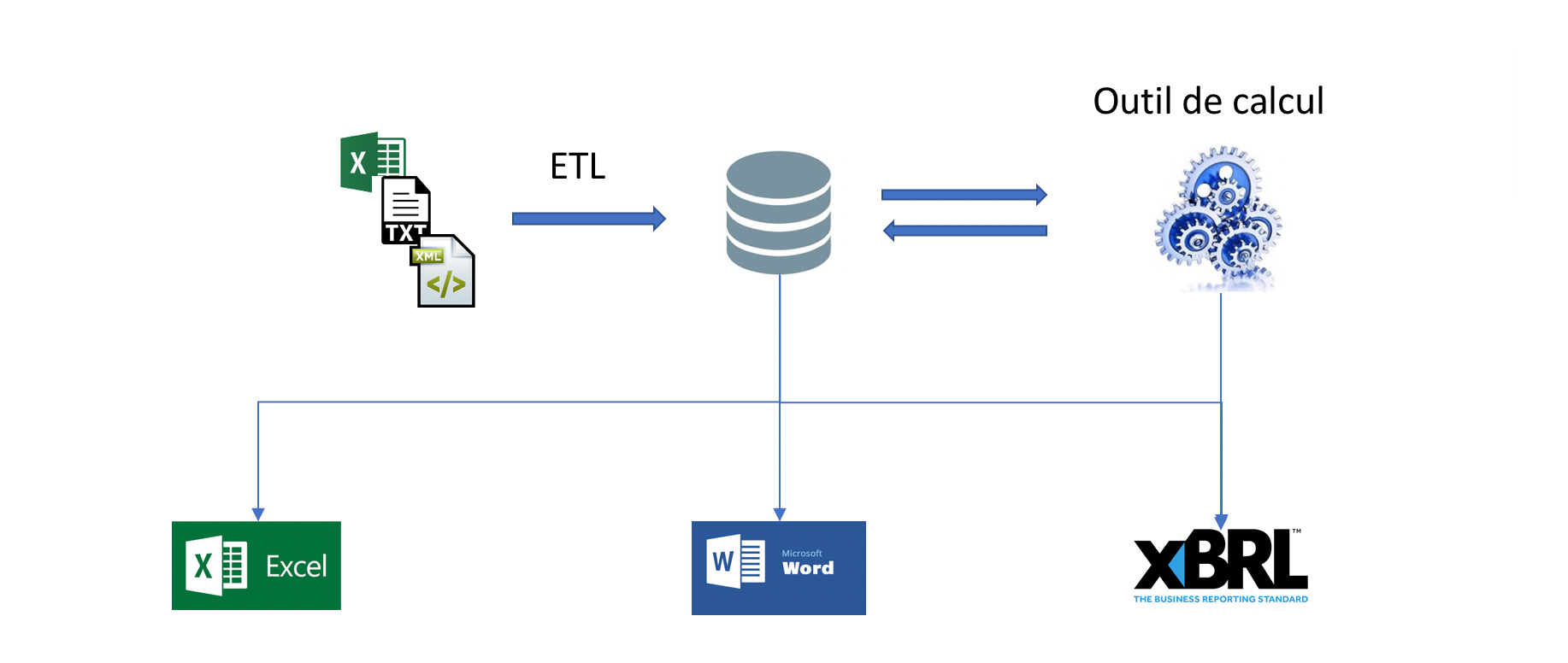
En poussant la logique à l’extrême, il est tout à fait possible d’envisager l’alimentation directe des bases sous-jacentes aux outils de calculs actuariels.
Tous les grands éditeurs de bases de données proposent leur ETL (Microsoft, Oracle, SAS, SAP …). Notons le cas particulier de Power Query, qui est un utilitaire gratuit intégré à Excel, peu connu du grand public ou pourtant très puissant. Microsoft Access peut également être vu comme un ETL, car il dispose de fonctionnalité d’importation de données, de traitements via les requêtes, et d’exportation (toutes les étapes d’un process pouvant être enregistrées sous forme d’une macro).
Centralisation des traitements
L’automatisation totale des traitements va nécessiter
• de centraliser toutes les données dans une base de données unique
• de développer un moteur de calcul unique (S1, S2, ORSA)
• de déverser les résultats dans la base de données
• d'intégrer dans ce moteur une solution de génération XBRL

Une des premières difficultés de ce travail consiste à construire une base de données permettant de répondre à toutes les exigences de reporting de Solvabilité 2. Il faut en effet être capable de produire les centaines de QRT, et être en mesure de faire le lien entre chaque donnée élémentaire et son code XBRL.
En fait, cette base existe déjà, car l’EIOPA met à disposition en téléchargement une base complète au format SQLite lors de chaque nouvelle taxonomie. Elle contient une table pour chaque état élémentaire du reporting S2. Les champs des tables sont nommés selon les références de lignes et de colonnes des états.
Il est donc possible de programmer l’alimentation automatique de ces tables, dans n’importe quel langage. Cette tâche n’est pas complexe en soit, mais va s’avérer longue en raison du nombre très important d’états à produire.
La base EIOPA contient toute la taxonomie nécessaire à la transformation des données en XBRL. Il n’est donc pas compliqué de programmer un moteur de génération d’instances XBRL Le programme devra va prendre chaque champ de chaque table, identifier ses dimensions et les transcrire en XBRL.
La base centrale étant constituée, elle peut servir à alimenter des maquettes Excel. Ces dernières peuvent être téléchargées du site EIOPA, ou encore sur e-Surfi (avec l’intérêt d’avoir les maquettes en français). La correspondance entre les noms de tables et les noms des cellules est élémentaire, et un module VBA pourra effectuer cette alimentation automatique.
Enfin, on pourra faire appel aux fonctionnalités de publipostage de Word pour insérer dans un rapport des champs de fusion. Tous les chiffres seront donc récupérés automatiquement de la base de données, sans recopie manuelle.
Synthèse
Les approches fast-close nécessitent un travail très important sur les projections de données, les méthodes actuarielles, et le suivi entre le prévisionnel et le réel. Il est certainement plus pertinent de déplacer ses efforts sur l’automatisation des process, qui constitue un vrai projet d’entreprise. Le développement d’une base centralisant données et résultats, et d’un moteur de calcul capable de lire et d’écrire dans cette base peut permettre d’atteindre un niveau très élevé d’automatisation, de la récupération de la donnée jusqu’à la production des instances XBRL.
*Tribune par Jérôme Sander, Actuaire Associé de Grant Thornton France, parue le 22 01 2019 dans le mensuel La Tribune de l’Assurance
|


